Содержание
Дубли контента – это частично или полностью одинаковый текст, картинки и прочие элементы наполнения сайта, доступные по разным адресам страниц (URL). Наличие дублей может значительно затруднять поисковое продвижение сайта.
По оценке специалистов, дублированный контент – самая распространенная ошибка внутренней оптимизации, присутствующая на каждом втором веб-ресурсе.
Как проверить, есть ли дубли на вашем сайте, и каким образом от них избавиться? Об этом мы расскажем в новом выпуске нашей рассылки.
Какие бывают дубли
Дубли бывают четкие и нечеткие (или полные и неполные).
Четкие дубли – страницы-копии с абсолютно одинаковым контентом, содержимым мета-тега Description и заголовка Title, доступные по разным адресам. Например, у исходной страницы могут появиться следующие дубли:
- зеркало с WWW или без;
- страницы с разными расширениями (.html, .htm, index.php, GET-параметром «?a=b» и т. д.);
- версия для печати;
- версия для RSS;
- прежняя форма URL после смены движка;
- и так далее.
Нечеткие дубли – частично одинаковый контент на разных URL.
В качестве примеров таких дублей можно привести следующие варианты:
- карточки однотипных товаров с повторяющимся или отсутствующим описанием;
- анонсы статей, новостей, товаров в разных рубриках, на страницах тегов и постраничной разбивки;
- архивы дат в блогах;
- страницы, где сквозные блоки по объему превосходят основной контент;
- страницы с разными текстами, но идентичными Title и Description.
Чем опасны дубли для продвижения
1. Затрудняется индексация сайта (и определение основной страницы)
Из-за дублей количество страниц в базе поисковых систем может увеличиться в несколько раз, некоторые страницы могут быть не проиндексированы, т. к. на обход сайта поисковому роботу выделяется фиксированная квота количества страниц.
Усложняется определение основной страницы, которая попадет в поисковую выдачу: выбор робота может не совпасть с выбором вебмастера.
2. Основная страница в выдаче может замениться дублем
Если дубль будет получать хороший трафик и поведенческие метрики, то при очередном апдейте он может заменять основную (продвигаемую) страницу в выдаче. При этом позиции в поиске «просядут», т.к. дубль не будет иметь ссылочной популярности.
3. Потеря внешних ссылок на основную страницу
Желающие поделиться ссылкой на сайт могут ошибочно ссылаться на страницы-дубли. Ссылочный вес будет «размазан» между страницами, и ситуация с определением наиболее релевантной версии усугубится.
4. Риск попадания под фильтр ПС
И Яндекс, и Google борются с неуникальным контентом, в связи с чем могут применить к «засоренному» сайту фильтры АГС и Panda.
5. Потеря значимых страниц в индексе
Неполные дубли (страницы категорий, новости, карточки товаров и т. д.) из-за малой уникальности имеют шанс не попасть в индекс поисковиков вообще. Например, это может случиться с частью товарных карточек, которые поисковый алгоритм сочтет дублями.
Как найти и устранить дубли на сайте
Будучи владельцем сайта, даже без специальных знаний и навыков вы сможете самостоятельно найти дубли на вашем ресурсе. Ниже дана инструкция по поиску и устранению дублированного контента.
Поиск полных дублей
Самый быстрый способ найти полные дубли на сайте – отследить совпадение тегов Title и Description. Для этого можно использовать панель вебмастера Google или популярный у оптимизаторов сервис Xenu. Поиск ведется среди проиндексированных страниц.
1. Ищем с помощью Google Search Console
Зайдите в консоль, выберите нужный сайт, далее в пункте меню «Вид в поиске» кликните по ссылке «Оптимизация HTML». На экране отобразится таблица, в которой следует обратить внимание на следующие параметры (Рис.1):
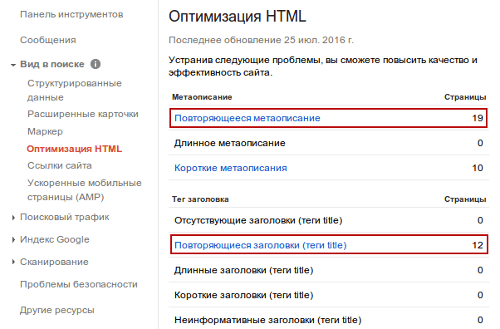
Рис. 1. Поиск четких дублей в панели вебмастера Google
При клике по данным ссылкам откроется список URL, для которых Google обнаружил повторяющееся мета-описание и счел их дублями. В списке могут попадаться и неполные дубли – страницы с разным контентом, но одинаковыми Title и/или Description.
2. Ищем с помощью программы Xenu
Если у вас нет доступа к панели вебмастера, можно использовать десктопный сервис Xenu. Скачайте его, нажмите «File», далее – «Check URL», затем укажите адрес сайта и запустите сканирование. После завершения проверки можно экспортировать данные в excel и отсортировать их по колонке «Title». Совпадающие заголовки будут указывать на дубли страниц.
3. Ищем в адресной строке браузера
Многие динамические адреса страниц-копий могут не находиться в индексе, и чтобы обнаружить такие дубли, можно воспользоваться адресной строкой браузера. Покажем на примере одного из сайтов, участвовавших в нашей рубрике «Экспертиза». Добавим разные окончания к исходному URL:
Контент главной страницы доступен как минимум по двум адресам:
- //decora-pro.ru
- //decora-pro.ru/index.php
Все страницы сайта отображаются одинаково при указании GET-параметра ?a=b:
- //decora-pro.ru/discount
- //decora-pro.ru/discount?a=b
Это техническая ошибка, порождающая страницы-синонимы, которые являются полными дублями.
Устранение полных дублей
Полные дубли появляются по различным причинам, поэтому для их устранения применяются разные способы.
1. 301 редирект для главной страницы
Если домен вашего сайта доступен с www и без этого префикса, укажите главное зеркало и пропишите правило редиректа в файле .htaccess.
Пример перенаправления на версию без www:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.(.*) [NC]
RewriteRule ^(.*)$ //%1/$1 [R=301,L]При обнаружении синонимов главной страницы (как в примере выше, когда главная страница открывается и с окончанием index.php) в .htaccess следует сделать редирект с дубля:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9} /index.php HTTP/
RewriteRule ^index.php$ //www.decora-pro.ru/ [R=301,L]- Минусы: высокая сложность метода.
- Плюсы: универсальное решение; защищает от появления новых дублей главной страницы.
2. Массовый 301 редирект
Единого рецепта массового редиректа для всевозможных дублей не существует. В каждом отдельном случае необходимо подбирать соответствующее ситуации решение. Массовое перенаправление можно настроить только с однотипных URL разного вида.
Частный пример: в разделах «Новости» и «Статьи» изменилась структура URL (перешли на ЧПУ), для такого случая можно настроить массовый 301 редирект следующим правилом:
RewriteCond %{QUERY_STRING} ^(id=(d+)&)?m=(news|articles)(&id=(d+))?$
RewriteRule ^index.php$ /%3_%2%5.html? [R,L=301]Еще один пример – из практики работы с движком WordPress. Этой CMS свойственно генерировать массу дублей одной страницы при добавлении комментариев пользователей. Такая страница получает окончание replytocom. Массовым редиректом можно направлять робота с любого дубля вида site.ru/statya_11.html?replytocom=2200 на его основную версию site.ru/statya_11.html, избавляясь одновременно от сотен или даже тысяч дублей.
Правило для этого случая следующее:
RewriteCond %{QUERY_STRING} replytocom=
RewriteRule ^(.*)$ /$1? [R=301,L]- Минусы: крайне высокая сложность, требует грамотного профессионального подхода. Метод не работает для URL с разной структурой.
- Плюсы: наиболее быстрый способ переправить роботов и пользователей с найденных дублей на основную страницу. Исключает появление новых дублей. Вес с дублей передается основной странице.
3. Запрет индексации в Robots.txt
Условия для использования метода те же, что и в предыдущем пункте: закономерность в структуре URL или нахождение адресов в одной директории.
Одним правилом, прописанным в файле Robots.txt, можно запретить индексировать новые дубли (в случае их появления) и удалить уже проиндексированные. Используется директива Disallow.
Пример Robots.txt:
User-agent: * Host: site.ru Disallow: /*? Disallow: /print/
Минусы: метод применим только в отношении робота Яндекса и не поддерживается Google.
Плюсы: наиболее быстрый способ запретить к индексации некоторые дубли и предотвратить появление новых.
4. Тег rel=canonical
Метод канонических адресов применим абсолютно для любых дублей и реализуется довольно просто.
В коде страницы-дубля (той, от которой нам необходимо избавиться) в разделе head требуется прописать тег rel=»canonical».
Например:
<link rel="canonical" href="//site.ru/canonical_page.html"/>
Это укажет роботу путь на каноническую (предпочитаемую) страницу, которая будет индексироваться и участвовать в поиске.
- Минусы: трудоемкая работа, при большом количестве страниц займет много времени.
- Плюсы: не требует профильных знаний, приветствуется поисковыми машинами. Вес с дублей передается основной странице.
5. Удаление с ошибкой 404
Избавиться от найденных дублей можно довольно просто – удалить их с сайта, оставив только основную страницу. После очередного апдейта они выпадут из индекса. При удалении страниц не забывайте о правилах оптимизации: оформите их в общем дизайне сайта, проинформируйте пользователей, что данная страница более не существует, и направьте на основную.
Важное примечание: после удаления дублей с сайта не забудьте удалить их также из индекса в панелях вебмастера и .
Минусы: не все дубли можно (и нужно) удалять (например версии страниц с рекламными метками); трудоемкая работа, занимающая при большом количестве страниц много времени. Не исключает появления новых дублей. Вес с дублей не передается основной странице.
- Плюсы: не требует специальных навыков программирования.
6. Готовые решения для популярных CMS
Разработчики популярных CMS предусмотрели ряд решений, предотвращающих появление дублей. При этом вебмастерам при работе с движком необходимо внимательно выставлять настройки. Если вы что-то упустили из виду и дубли все же появились, никогда не поздно все исправить и устранить копии. Внятные инструкции по настройкам движка и использованию SEO-плагинов можно найти на профильных блогах и на форумах WordPress, Joomla, Drupal, Битрикс, а также других широко представленных CMS.
Полезные SEO-плагины для борьбы с дублями:
- WordPress: All in One SEO Pack, Clearfy;
- Drupal: Global Redirect, Page Title;
- Joomla: Canonical Links All in One, JL No Dubles.
7. Борьба на уровне движка
Универсальное решение для самых разных CMS – предупредить появление новых дублей на уровне движка. Необходимо задать такое условие, при котором в процессе обработки адресных ссылок CMS будет отличать «хорошие» от «плохих» и отображать в строке браузера только те, которые разрешены правилом. Это позволит избежать формирования страниц-синонимов (со знаком «/» и без него, с ненужным окончанием .html, GET-параметрами и проч.), однако не защитит от возникновения дублей, если у страниц не будут уникализированы Title и Description.
Для реализации данного метода в файле .htaccess необходимо включить следующее правило:
RewriteEngine on
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^(.*)$ index.php [L,QSA]Кроме этого, следует реализовать необходимые проверки в самом движке.
Метод отличается высокой сложностью и требует обращения к специалистам по разработке.
- Минусы: крайне высокая степень сложности.
- Плюсы: предотвращает появление страниц-синонимов.
Поиск неполных дублей
1. Ищем при помощи вебмастера Google или сервиса Xenu
Алгоритм действий в этих сервисах абсолютно такой же, как и для поиска полных дублей. Единственное отличие заключается в том, что среди найденных дублей необходимо отобрать те страницы, которые имеют идентичные Title и/или Description, но совершенно разный контент.
В результате поиска в Google мы обнаружили группу неполных дублей (Рис. 2).

2. Ищем в строке поиска Яндекса или Google
Страницы с частично похожим контентом, но разными мета-данными указанным выше способом выявить не удастся. В этом случае придется работать вручную.
Для начала условно выделите зоны риска:
- скудный контент (сквозные блоки по объему превосходят основной текст страницы);
- копированный контент (описание схожих товаров);
- пересечение контента (анонсы, рубрики/подкаталоги, фильтры, сортировка).
Из каждой группы выберите несколько страниц.
Для наглядной иллюстрации примера мы воспользовались одной из карточек товаров на сайте мебельного магазина, проходившего аудит в нашей рубрике «Экспертиза». Вероятность появления дублей здесь достаточно высока, так как в карточках преобладают картинки и сквозные блоки, а уникальный контент сведен к минимуму.
Указываем в строке поиска Google фрагмент текста из описания товара, заключенный в кавычки, и домен сайта с оператором site: (Рис. 3).
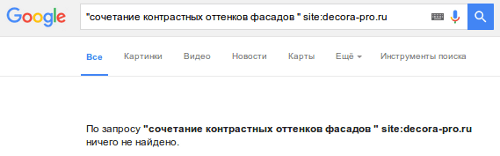
На представленном скриншоте хорошо видно, что карточка товара отсутствует в индексе Google. Проверка в Яндексе данной страницы, а также товаров из других категорий этого сайта дала аналогичный результат. Соответственно, данные страницы потеряны для привлечения трафика из поиска.
Также для примера проверим отрезок текста одной из новостей магазина (Рис. 4).
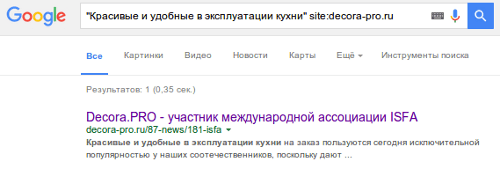
Аналогично поступим и с парой других новостей. По запросу поиск выдает ссылку на список всех новостей, но ни одна уникальная новость не попала в индекс. Часто бывает обратная ситуация: в индекс попадает несколько дублей (сама новость, анонс новости в списке новостей, анонс новости на разных страницах пагинации (если пагинация настроена некорректно)). В таком случае в выдаче появляется сразу несколько ссылок на один и тот же контент.
Проверьте аналогичным способом (при помощи отрезка текста и оператора site:) фрагменты контента товарных страниц, страниц услуг, новостей, анонсов и других значимых для продвижения разделов. При обнаружении проблем переходите к следующему шагу.
Устранение неполных дублей
1. Оптимизация мета-данных
Для частично дублированных страниц, найденных в Search консоли Google, необходимо переписать и уникализировать Title и Description. Советы и рекомендации по работе вы найдете в нашей статье. После апдейта данные страницы должны выйти из категории дублей.
2. Оптимизация контента
Если вы не находите значимых страниц в индексе поисковых систем, следует устранить причину их низкого качества:
- увеличить основной блок контента, поднять текст к началу страницы; сократить слишком длинное меню слева;
- в страницы с очень похожим описанием внести правки: оптимизировать Title (например заменить лаконичное «Афина» на «Современная кухня из ЛДСП «Афина» от 19 000 рублей – DECORA.PRO»), подчеркнуть и особо выделить отличительные особенности товара или услуги; уникализировать контент за счет комментариев и т. д.;
- внимательно следить за мета-данными (для каждого URL должен быть уникальный контент, уникальные Title и Description).
3. Оптимизация структуры и перелинковки
Речь идет о странице анонсов и пагинации. Рубрику анонсов рекомендуется закрывать от индексации, в том числе и постраничную разбивку (рекомендации по работе читайте здесь). Это необходимо, чтобы контент новости не дублировался и ссылка из поиска вела исключительно на саму новость.
Другой вариант – помещать на страницу анонсов уникальные тексты, но при этом в любом случае соблюдать правило оптимизации постраничной разбивки. Уже существующие дубли новостей или статей можно удалить из индекса (в кабинете вебмастера Яндекса или Google), а в их коде прописать rel=canonical, отправляя робота и трафик на основную страницу новости.
К примеру, для движка WordPress характерно, что фрагмент поста в виде анонса попадает в архив дат, в разные рубрики, индексируется на разных страницах пагинации, в результате чего в поиске могут появиться ссылки как на сам пост, так и на его неполные дубли (Рис. 5).
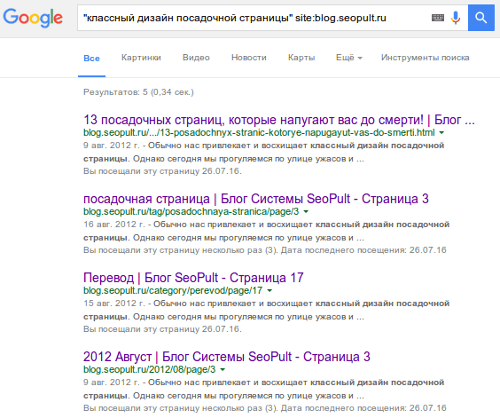
Их следует удалить из индекса, а предотвратить появление новых поможет WP-плагин Clearfy.
Если говорить об анонсах товаров в разрезе разных категорий (например, один и тот же диван может быть в разных рубриках: раскладные, кожаные, трехместные и т.д.), то в этом случае можно не использовать анонс описания товара в списке позиций, а выводить только ссылку на него (наименование) в сопровождении изображения.
Проверяйте и устраняйте дубли
Проблема дублей не нова, но очень часто остается за рамками внимания вебмастеров и оптимизаторов. Однако она имеет большое значение для обеспечения качества поиска, о чем нам напоминают представители поисковых машин. Как можно увидеть из примеров, многие важные страницы сайтов не попадают в индекс и не приводят трафик или, наоборот, попадают в многократном размере и только засоряют его. В любом случае деньги, потраченные на продвижение такого сайта, расходуются нерационально. Обязательно проверьте ваш сайт на наличие дублей, устраните их доступными из перечисленных выше методами или закажите оптимизацию у специалистов.
SeoPult:
